LLM 大语言模型介绍
1. 什么是语言模型?
1.1 定义
定义:语言模型 是一个用来估计文本概率分布的 数学模型。
作用:根据给定的文本,预测下一个最可能出现的单词。
例如 BERT、ChatGPT 都是语言模型。
1.2 N-gram:最简单的语言模型
N-gram 模型通过将文本分割成连续的 n 个词的组合,来近似描述词汇序列的联合概率。
算法思想:假设一个词出现的概率仅依赖于它前面的 N - 1 个词。在预测下一个单词概率时,只考虑它前面的 N - 1 个词,即 P(W(i) | W(i-1), … , W(i-n+1))
对于:“孙悟空三打白骨精”,
N = 1 时,unigram = {孙悟空},{三},{打},{白骨精}
N = 2 时,bigram = {孙悟空,三},{三,打},{打,白骨精}
N = 3 时,trigram = {孙悟空,三,打},{三,打,白骨精}
由上可见,这里的 gram 指的是一个字或者一个单词。
1.3 NPL中的分词
目的是把语料库中的句子划分成 gram,也就是我们常听说的 token。
子词:是指单词的一部分,通常是一个单词的较小组成部分。
我们将单词切分成更小的部分,以便更好处理 未登录词(revolutionizing -> revolution and ##izing)、拼写错误、词汇变化等问题。
1 | from transformers import BertTokenizer |
上述代码运行结果:
1 | ['natural', 'language', 'processing', 'is', 'fascinating', ',', 'and', 'it', "'", 's', 'revolution', '##izing', 'the', 'way', 'we', 'interact', 'with', 'technology', '.'] |
1.4 总结
N-gram 的优点:计算简单。
缺点:无法捕捉到长距离的词汇依赖关系。
虽然 N-gram 存在局限性,但启发了后来的自然语言处理技术。
2. 词向量
2.1 定义
在计算机视觉领域,我们可以用 RGB 值或者其他数值形式来描述并存储图像。但在自然语言处理领域,我们很难将语句转换成计算机能理解的形式。
词向量因此应用而生,它将语句转换成 对应数值向量的表达形式,便于计算机读取和运算。
方法:独热编码、分布式表示(Word2Vec、Glove、FastText)
2.2 独热编码表示词
举个例子:
v(“自然”) = [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] ∈ Rⁿ
v(“语言”) = [0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 …] ∈ Rⁿ
其中,n 代表字典的大小,即字典中一共包含 n 个词。
缺点:
- 高维度:独热编码(One-Hot)需要为词汇表中的每个词创建一个单独维度
- 稀疏性:One-Hot 向量中大部分元素为 0
- 缺乏语义信息:无法捕捉单词之间相似性或者语义关系(称为:词汇鸿沟)
- 无法处理未知词汇:因为需要提前定义一个固定的词汇表
2.3 分布式表示词
表示学习:将词汇、短语或文本表示成稠密、低维度的实值向量。这些向量捕获了语义信息,使得相似的词汇或概念在向量空间中有相似的表示。
基本思想:
-
通过训练过程,将词典里的每个单词转换为一个固定长度的低维向量。
-
所有这些向量组成一个词的向量空间,每个词向量在这空间中都代表一个点。
-
在词向量空间中定义 “距离” 度量,以便衡量单词之间的相似性。
总的来说:词的分布式表示是一种能刻画语义之间相似度,并且维度较低的稠密向量表示。
例如某个词被表示为 [0.75, -0.27, -0.91, 0.35, …] 向量。
2.4 词向量有什么含义
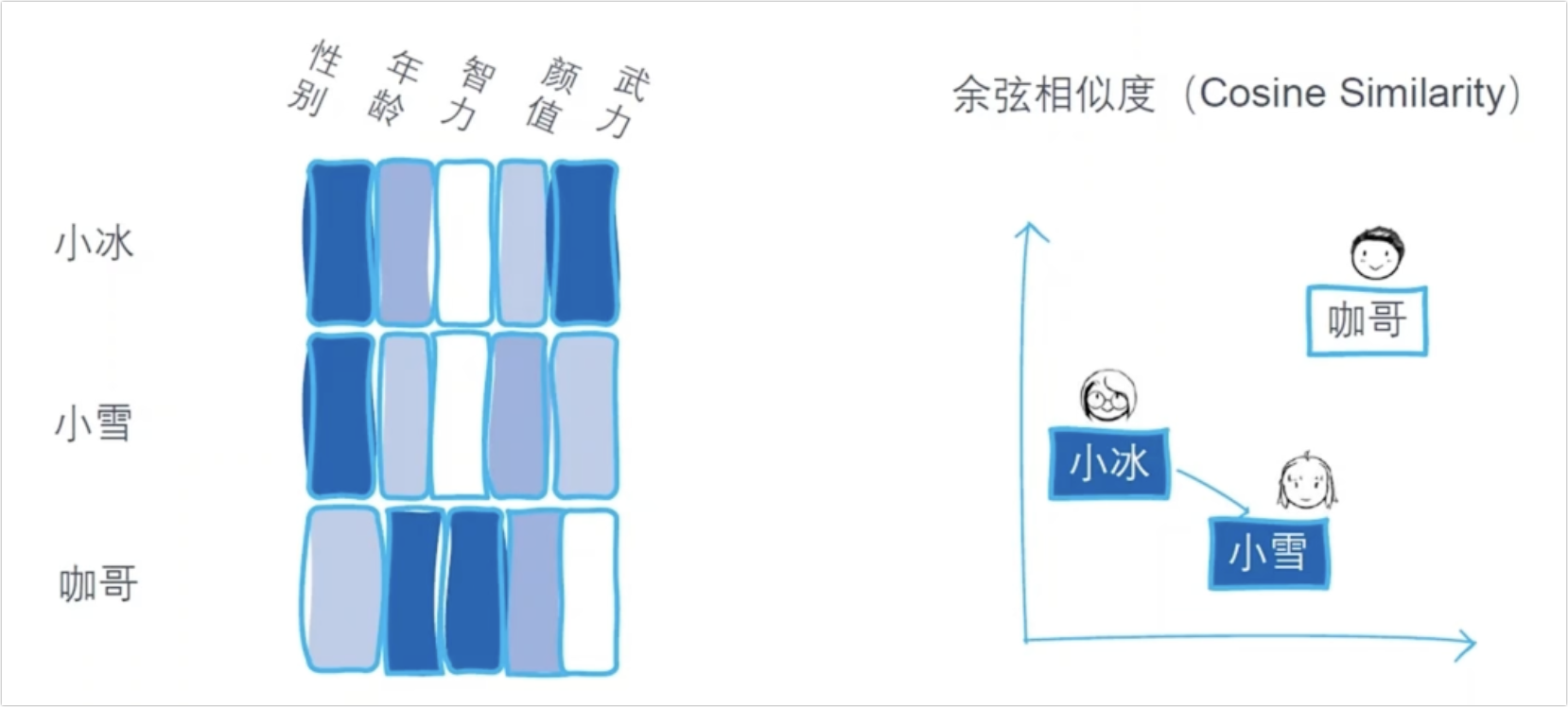
以上图为例,我们在评论一个人的时候会有不同维度的考量,例如性别、年龄、智力、颜值和武力等。而词向量也是类似的,只不过它的维度可能比较高,我们可能无法理解其中的具体含义。然而我们依然可以用 余弦相似度 来考虑两个词之间的距离。
2.5 词嵌入
这是一个概念,由上文我们可以知道,词向量指的是:一个词对应一个实际数值向量。我们可以说,“cat” 这个词的词向量是一个 x 维的向量。
词嵌入:用于描述将词映射到向量空间的过程或者方法,包括训练算法和生成的词向量空间。我们可以说,使用 Word2Vec 算法来进行词嵌入。
3. Word2Vec
3.1 简介
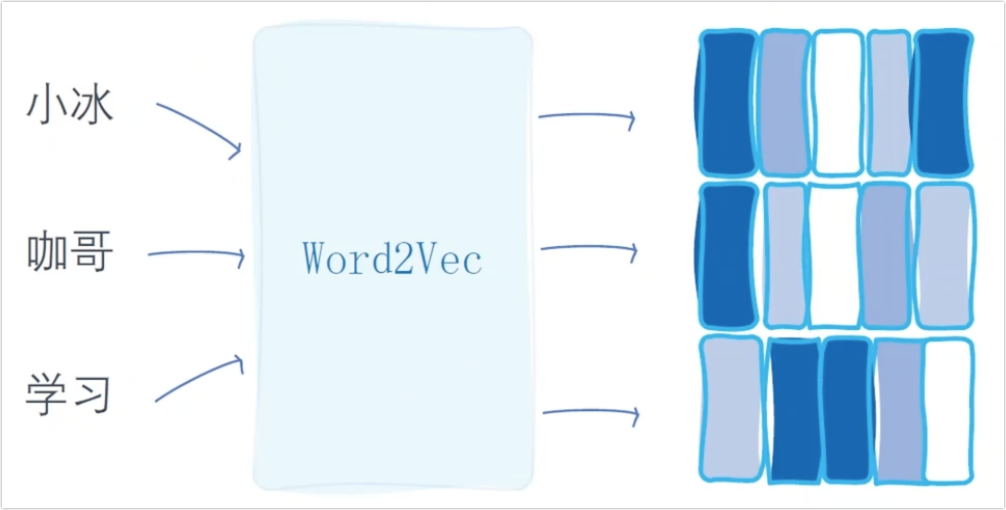
Word2Vec 将词典中的每个词都表示成固定长度的向量,并且取一些实际值。
例如,今 -> [0.2154521, -2.326536, -3.3652666, 2.12255521,…]。10维的 One-Hot 表示10个词语,10维的向量可以表示无数个词语。
两种实现方式:
- CBOW(Continuous Bag of Words):通过给定上下文词汇(周围词)来预测目标词汇(中心词)
- Skip-gram 模型:通过给定目标词汇(中心词)来预测上下文词汇(周围词)

3.2 模型结构
NPLM(神经概率语言模型):
- 输入层将单词映射到连续的词向量空间
- 隐藏层通过非线性激活函数学习单词间的复杂关系
- 输出层通过 Softmax 层产生下一个单词的概率分布
 wechat
wechat alipay
alipay